What did we try to improve with this document classifier?
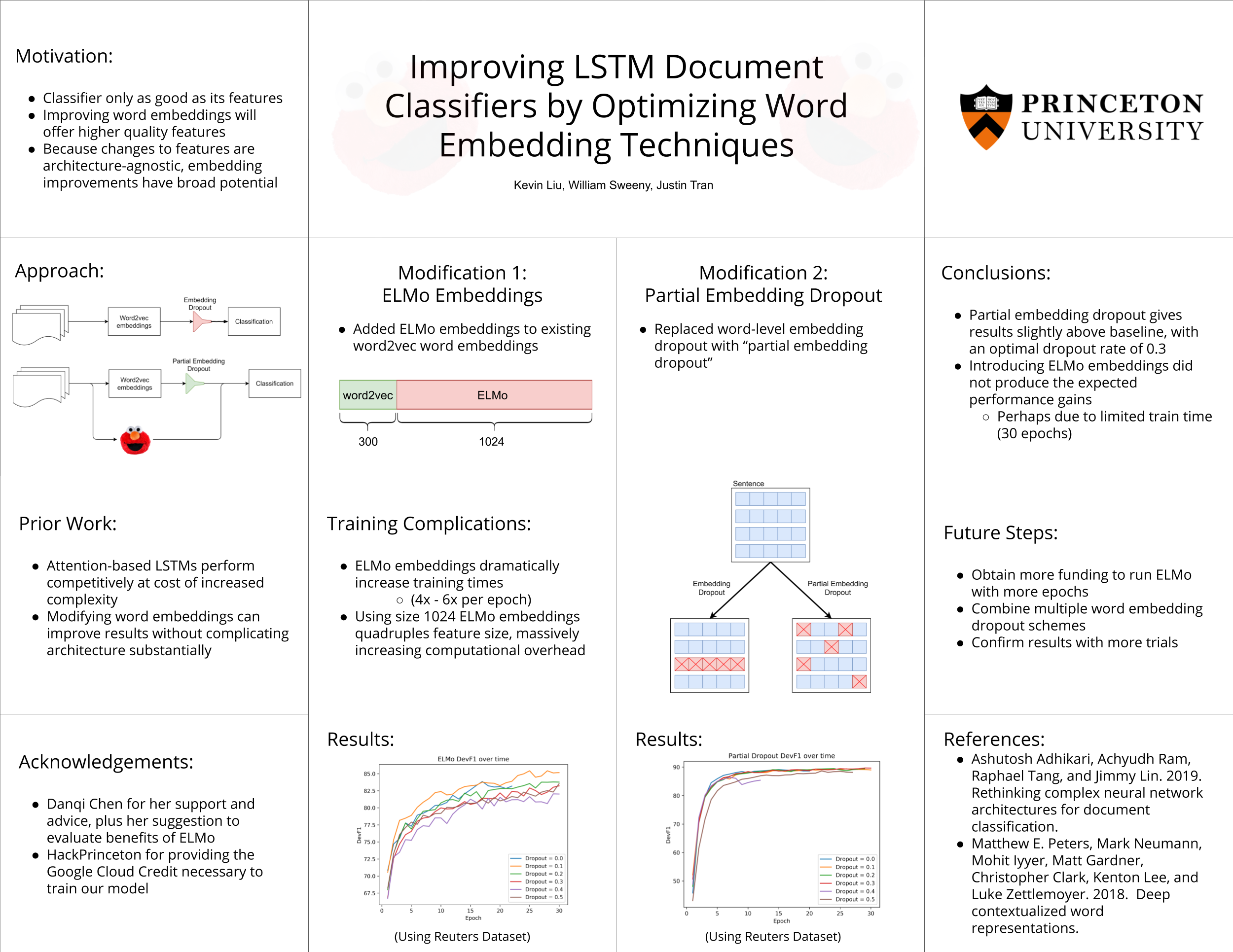
This project aims to modify the LSTM Reg architecture defined by Adhikari et al (2019). We attempt to improve upon the original architecture by introducing ELMo word embeddings (Peters et al., 2018) and a different schema for implementing dropout to augment the original model’s word-level embedding dropout. We assess the impact of these word embedding techniques by running our model against a document classification task using the AAPD and Reuters datasets. As a baseline, we compare our results to the unmodified architecture, and analyze the differences in classification F1 score between our modified architecture and the original.
What is ELMo and how do these word embeddings improve upon standard embeddings?
For a nice introduction to word embeddings and ELMo, please refer to this amazing explanation from Jay Alammar. It was actually used during our lectures to explain the concept.
Essentially, it should give more granularity and detail to our data set.
What were the results of the research?
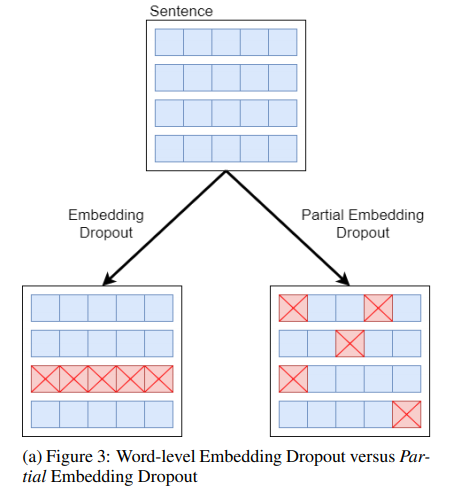
For greater detail, please check out our official paper below. Here’s a quick summary of the results though: Partial embedding dropout was a success and provided greater accuracy but the introduction of contextualized ELMo word embeddings was disappointing, increasing train times substantially while offering diminished performance.
Though we were able to achieve F1 scores above the baseline using partial embedding dropout, further research is required in order to compute the F1 standard distribution and determine the precise effect size of our improved embedding dropout scheme.
Where can I find the most pivotal details?
All code can be found in the Github repo.
The full paper can be found here.